
More Context Is Not Better Context
The context engineering movement is optimizing the wrong variable. The problem was never how much context your agent has. It’s what that context is made of.


There’s a belief running through the agentic AI stack right now, mostly unexamined, that sounds like common sense: agents fail because they don’t have enough context. Give them more. Fill the window. Upload the docs, the schema, the runbooks, the Slack threads, the lineage, the README. If the agent still gets it wrong, the diagnosis is always the same: more context.
This belief is producing a cottage industry. Million-token context windows. Elaborate RAG pipelines fetching everything that might be relevant. The underlying assumption is that the problem is information deficit and the cure is information abundance.
The research says something different. And it’s not subtle.
The effective window is not the advertised window
LLM providers market their models by context window size. Gemini 1.5 Pro: one million tokens. GPT-4.1: one million tokens. Llama 4: ten million tokens. The implicit claim is that more tokens in the window means more information the model can use.
This claim is false in a specific, measurable way.
In September 2025, Norman Paulsen introduced the concept of the Maximum Effective Context Window (MECW): the actual window within which a model produces reliable output, as distinct from the Maximum Context Window (MCW) it’s technically capable of accepting. Across hundreds of thousands of data points and multiple state-of-the-art models, the MECW was found to be dramatically smaller than the MCW, in some cases by more than 99%. A few top-of-the-line models failed with as little as 100 tokens in context. Most showed severe degradation in accuracy by 1,000 tokens. The MECW also shifts based on problem type, meaning there’s no single safe threshold. The ceiling depends on what you’re asking, not just how much you’re providing.
Chroma Research’s July 2025 “Context Rot” report drove the same point home with a different methodology. Evaluating 18 models across tasks held deliberately simple to isolate the effect of context length alone, they found consistent performance degradation as input length grew. Not just on hard tasks. On trivially simple ones. Their framing cuts to the mechanism: context must be treated as a finite resource with diminishing marginal returns. Every token added depletes an attention budget. Add enough tokens and you’re not giving the model more to work with. You’re giving it more to get confused by.
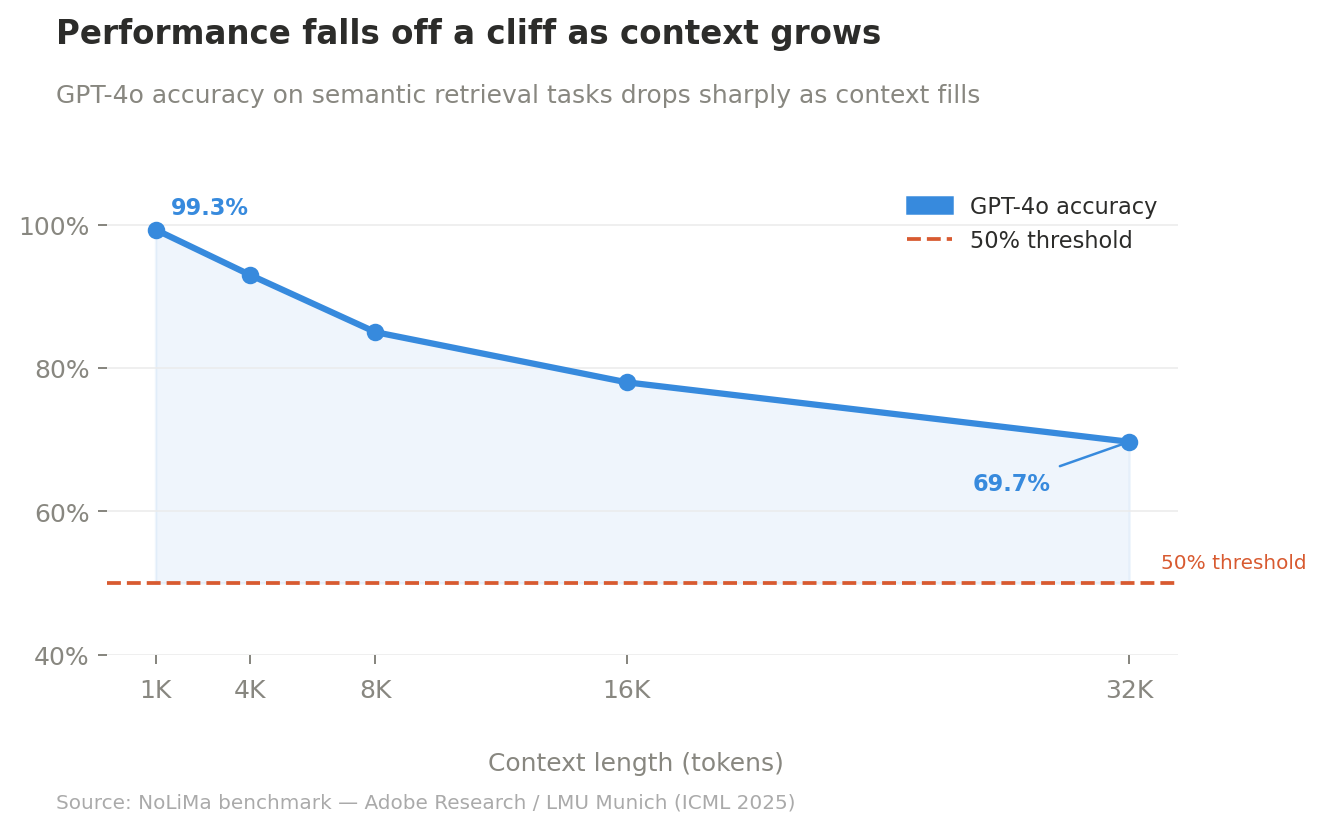
The NoLiMa benchmark from Adobe Research and LMU Munich (ICML 2025) made the collapse concrete. Evaluating models that advertise 128K+ token support on tasks requiring genuine semantic inference rather than keyword matching, they found that 10 of 12 models dropped below 50% of their short-context baseline by 32K tokens. GPT-4o fell from 99.3% to 69.7% at 32K. Even the top reasoning models, o1, o3-mini, and DeepSeek-R1, scored below 50% on the harder benchmark variant at that length. The Needle in a Haystack tests that models ace in marketing materials measure lexical retrieval. Real tasks don’t look like that.
There’s also a cost dimension that rarely enters this conversation. Self-attention has quadratic computational complexity: doubling sequence length quadruples cost. Manus, building one of the most sophisticated production agentic systems publicly documented, reports an average input-to-output token ratio of 100:1. Context is the overwhelming cost driver. They note explicitly that even 128K context windows are “often not enough, and sometimes even a liability.” The arms race toward longer windows is, economically, mostly a race toward more expensive failure.
There’s a name for the tax you pay as context fills: context rot. And you’re paying it right now, whether you know it or not.
The architecture has a blind spot. It’s in the middle.
Before the context window fills to the point of rot, there’s a structural problem with how models read what’s already in it.
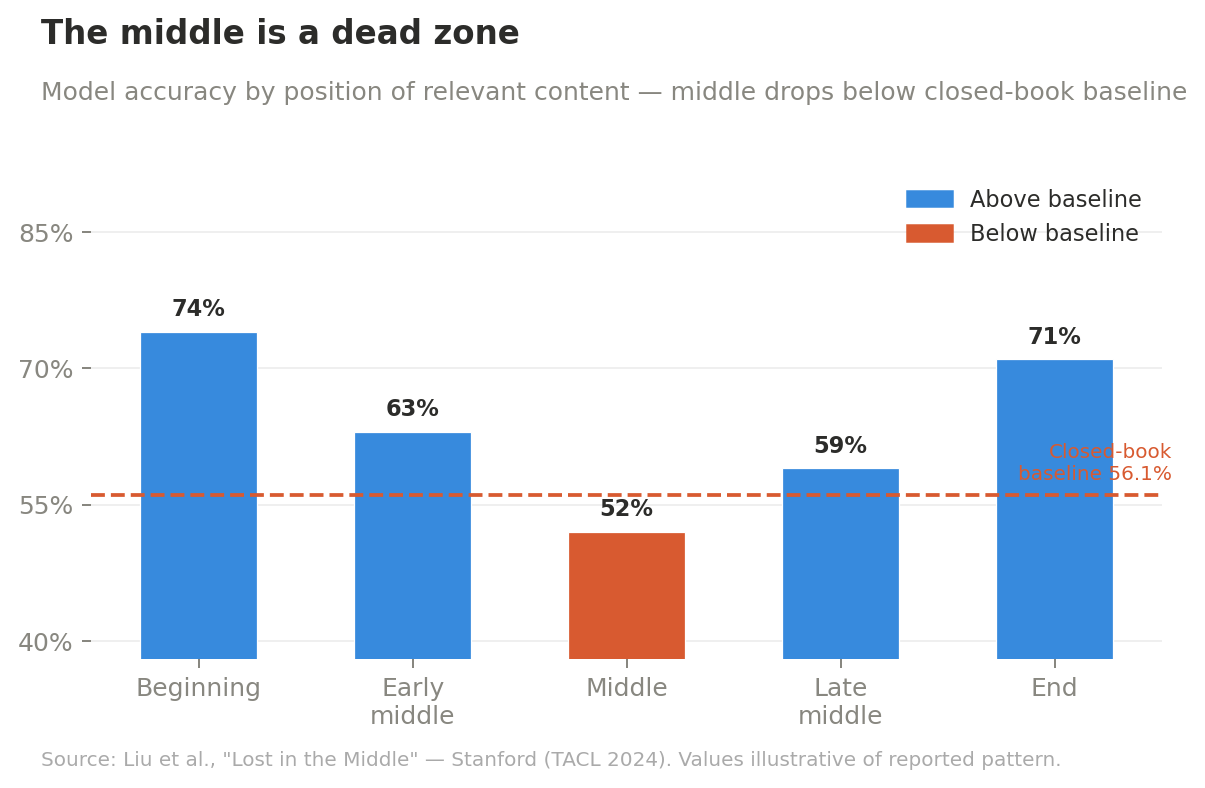
The “lost in the middle” phenomenon was first documented rigorously by Stanford researchers in 2023 and has been robustly replicated and theoretically explained since. The pattern is consistent: model performance follows a U-shaped curve based on where in the context relevant information appears. Information at the beginning benefits from primacy bias. Information at the end benefits from recency bias. Information in the middle sits in a dead zone.
The original Stanford result is striking on its own: in 20- and 30-document settings, GPT-3.5-Turbo’s accuracy dropped by more than 20 percentage points when the relevant passage was buried in the middle, falling below its 56.1% closed-book baseline. The model performed better relying purely on its training data than when it was given the right answer in the wrong position. More context, worse result.
Three independent 2025 papers established something more alarming: this bias is not a training artifact that better models will eventually fix. It’s mathematically baked into the architecture from initialization.
MIT researchers proved that causal masking inherently biases attention toward earlier positions. A separate paper proved that residual connections guarantee recency bias independently of positional encodings. And a March 2026 paper delivered the definitive result: an exact, closed-form mathematical proof that the U-shape is a topological constraint of decoder-only architectures. The authors tested untrained, deep LLMs before any training data whatsoever and found the U-shaped gradient topology fully formed at Step 0. They called it a “topological birthright.” It does not go away with scale or training.
Enterprise testing in 2026 confirms the persistence. Information placed at the beginning and end of context achieves 85-95% accuracy; the middle drops to 76-82% even in today’s best models.
Stuffing a context window is not a neutral act. The order and position of information inside the window is as consequential as whether the information is present at all. Most teams filling their context windows with everything-that-might-be-relevant are burying the most critical content in the middle by default, the worst place it can be.
Distractors are worse than nothing
It’s not just that irrelevant context is unhelpful. Certain kinds of irrelevant context, specifically topically related but non-answering content, actively degrades performance below the baseline of no context at all.
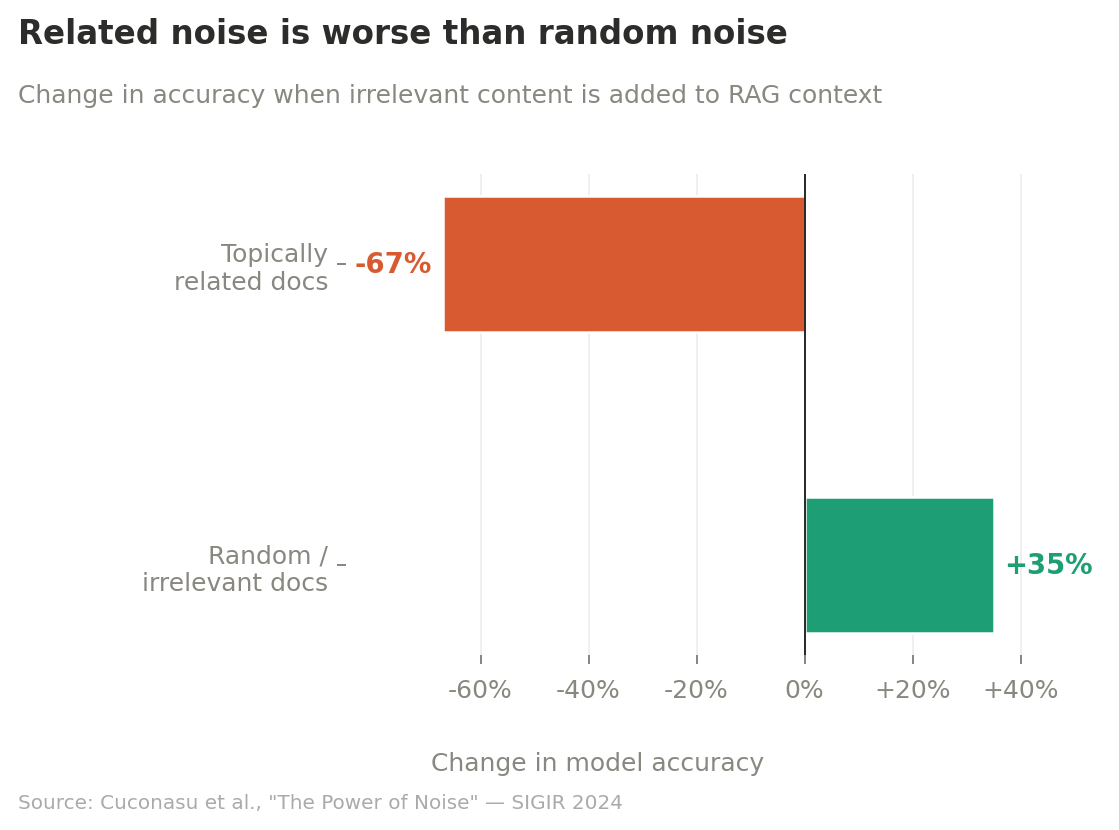
The most direct evidence comes from Cuconasu et al.’s “The Power of Noise” (SIGIR 2024). Adding related-but-not-answering documents caused accuracy degradation of up to 67%. Adding just one related distractor caused drops of up to 24 percentage points. The control condition with completely random, irrelevant documents improved accuracy by up to 35%. That’s roughly a 100-percentage-point swing between the effects of topically related noise versus random noise. The documents that look most relevant to the question but don’t answer it are the most dangerous things you can put in a context window.
Chroma’s Context Rot report replicated and extended this. Even a single distractor noticeably reduced success rates. More unexpectedly: coherent, structured haystacks hurt more than shuffled ones. When irrelevant context had logical narrative flow, models performed worse than when those same sentences were randomly scrambled. Semantic relatedness and internal coherence in the noise make the signal harder to find, not easier.
The EMNLP 2025 paper “Context Length Alone Hurts LLM Performance Despite Perfect Retrieval” took the most controlled approach. Even with the right answer always present in the window, performance degraded 13.9% to 85% as context length increased. Most strikingly: when all irrelevant tokens were fully masked so models attended only to the relevant content, there was still at least a 7.9% performance drop at 30K masked tokens. Context length itself is causal. The presence of surrounding information, even invisible information, degrades reasoning.
Translate this to data contexts. A data agent querying an analytics system is almost always operating in a distractor-rich environment. The schema contains dozens of tables, most of which don’t answer the current question but are semantically adjacent to the ones that do. The lineage graph contains dozens of upstream and downstream hops, most of which are noise relative to the specific transformation under investigation. The business definitions catalog contains dozens of related metrics, many of which share names, overlap in scope, or differ only in how a single edge case was handled three years ago.
In data contexts, topical adjacency is the default. Every additional table you fetch, every additional column you include, every additional upstream source you trace is statistically more likely to be a distractor than a signal. The impulse to include everything isn’t a safety net. It’s an active degradation of every inference your agent makes.
What good context is actually made of
If more is not better, what is? The picture from research and production practice converges on four properties.
Density. Every token should be doing work. Anthropic’s engineering team frames the core principle precisely: find “the smallest possible set of high-signal tokens that maximize the likelihood of your desired outcome.” Not the largest set. The smallest. Microsoft Research’s LLMLingua series demonstrated this quantitatively: prompt compression at up to 20x achieved only a 1.5 percentage point performance loss. In some configurations, compressed prompts outperformed the originals. The tokens you remove can be worth more than the tokens you keep.
Structure. Position matters as much as content. Instructions and constraints belong at the start, where primacy bias works in your favor. The most relevant retrieved facts belong near the end, where recency bias produces the strongest signal. JetBrains Research’s NeurIPS 2025 work (Lindenbauer et al.) found that simple observation masking, preserving the chain-of-thought while dropping the environment observations driving context bloat, matched or outperformed more sophisticated LLM summarization approaches, reducing cost by around 50% without degrading task performance. The structure of reasoning is precious; the bulk of observation data is expendable.
Specificity. Context should be scoped to the question being asked right now. Anthropic’s engineering team recommends just-in-time retrieval over pre-loading: maintain lightweight identifiers and dynamically load data at runtime, rather than front-loading everything that might be relevant. Manus’s production architecture operationalizes this directly, treating the file system as “the ultimate context” and pulling from it surgically rather than ingesting it wholesale.
Authority. Good context carries provenance. A definition of “revenue” is more useful when it identifies who approved it, when, and what exceptions apply. Without authority signals, a model treats a casual comment and a formally approved definition as equivalent input. In data contexts especially, where the same field name means different things in different systems and exceptions accumulate over years of edge cases, authority is often the difference between a correct answer and a confident wrong one.
The data context problem is worse than you think
The general literature on context rot and lost-in-the-middle applies broadly. But data contexts have a structural property that makes the problem categorically worse: they have no intrinsic semantics.
When a coding agent reads a function signature, it receives type information for free. The parameter names are meaningful. The return type is constrained. The compiler enforces contracts. The semantics are embedded in the artifact itself.
When a data agent reads a column named rev in a Postgres table, it gets nothing. rev could be revenue, revisions, or a reversal entry. The agent has to infer meaning from external context, a catalog entry, a semantic layer definition, a description field, that was written by a human, may be months out of date, and was almost certainly written for human readers rather than machine consumers.
The empirical consequences are severe and well-documented.
Spider 2.0 (ICLR 2025 Oral) built an enterprise text-to-SQL benchmark using real-world schemas where the average database contains 812 columns, with some exceeding 3,000. The performance collapse is stark: o1-preview achieves 17-21% accuracy on Spider 2.0 versus 91.2% on Spider 1.0, a 70-point drop when schema size scales from academic to enterprise. The error analysis is telling: 27.6% of failures are wrong schema linking and 16.6% are wrong column linking. The agent isn’t failing because of a reasoning deficiency. It’s failing because the schema is a distractor-dense environment.
SAP Research’s April 2025 study on enterprise data engineering found that when tested on actual enterprise data with customer-defined columns, the custom schema extensions that encode an organization’s most important domain-specific logic, F1 scores fell to near zero. These aren’t obscure edge cases. They’re the columns most likely to be queried by an analytics agent.
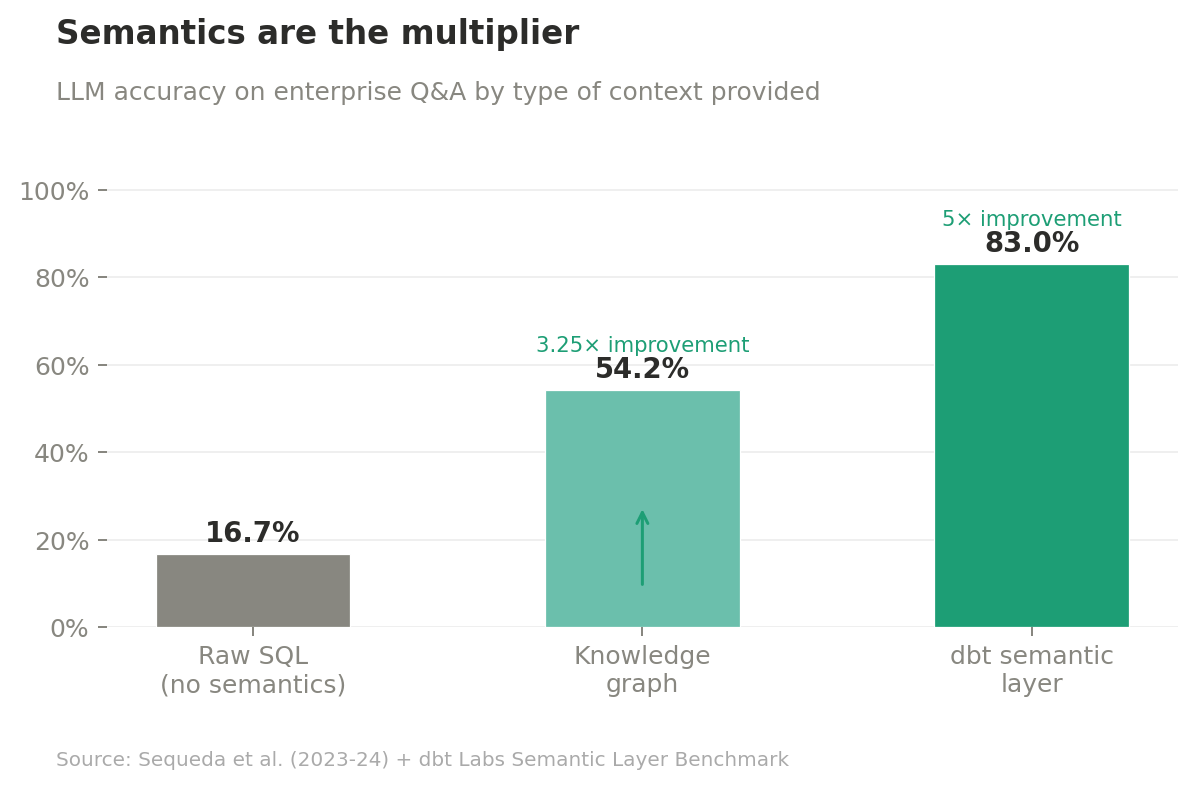
The contrast with a properly built semantic layer makes the gap concrete. Sequeda et al. tested GPT-4 on enterprise question answering two ways: direct SQL prompting versus a Knowledge Graph representation with ontology and semantic structure. Zero-shot SQL prompting achieved 16.7% accuracy. The Knowledge Graph representation achieved 54.2%, a 3.25x improvement. For complex, high-schema questions, the SQL-only approach scored 0%; the KG approach scored 35%. dbt Labs replicated this using their semantic layer with GPT-4: 83% accuracy versus the 16.7% raw SQL baseline, a 5x improvement. Adding natural language column descriptions moved several question categories from 0% to 100% success.
The semantic layer doesn’t add tokens. It changes what each token means. That’s the difference between volume and density.
MotherDuck’s analysis of the BIRD benchmark surfaces one final counterintuitive result: on schemas with intuitive, self-explanatory column names, adding schema comments actually hurt performance. More context, worse result, because the comments introduced distractor noise into a context that was already working.
Adding more semantically thin data to the context window is not additive. It’s dilutive. The data agent problem is not a scaled-up version of the code agent problem. It’s a categorically different problem, and the gap is structural.
The right diagnosis
The Microsoft and Salesforce multi-turn study (May 2025) crystallizes what’s actually happening. Testing 15 LLMs across 200,000+ simulated conversations, they found an average performance drop of 39% when information was spread across multiple conversation turns versus delivered in a single well-structured prompt. This held across every frontier model tested. The degradation decomposed into a 16% capability loss plus a 112% increase in unreliability. The agent didn’t just get worse; it got less predictable.
That 112% reliability collapse is the real problem. Not that the agent can’t do the task. It’s that you can’t tell when it will and when it won’t.
The context engineering movement correctly diagnosed that agents fail because they lack the right information at inference time. But “right information” got conflated with “more information,” and the prescription to fill the window is making the underlying problem harder to see and harder to solve. It’s producing agents that are comprehensive but unreliable rather than scoped but trustworthy.
The actual diagnosis: agents fail because their context is low-density, poorly structured, semantically impoverished, and without authority. The fix is not volume. It’s curation infrastructure that produces high-signal, structured, scoped, and authoritative context as a byproduct of work, not as a separate governance exercise bolted on afterward.
For data specifically, that means things most organizations haven’t built yet. Semantic layers that encode business meaning at the column level, not just the table level, with the 5x accuracy improvement that implies. Decision records that attach authority to definitions: not just what “revenue” means but who decided it, when, and what exceptions apply. Retrieval scoped to the question being asked rather than the full schema that might be related. Context assembly that puts critical content at the edges of the window, where the model is architecturally equipped to use it, rather than organizing it for human readers.
The question to ask about any piece of context you’re assembling is not “could this be relevant?” It’s: does this raise or lower the signal-to-noise ratio of the window?
Most of what goes into most data agent context windows today fails that test.
Building less
The teams building the most reliable data agents right now are not building the most comprehensive context pipelines. They’re building the most aggressive curation pipelines. They’re asking not “what can I include?” but “what can I afford to exclude?” They’re treating the context window as a scarce resource to be managed rather than a pool to be filled.
The ACE framework from Stanford and SambaNova (October 2025) operationalized this directly, maintaining evolving, structured context playbooks rather than accumulating raw history. The result: +10.6% improvement on complex agent tasks and 86.9% average latency reduction versus context-accumulation baselines. Less context, structured deliberately, dramatically outperformed more context assembled passively.
This isn’t an argument against rich data contexts. It’s an argument for building the infrastructure that makes rich contexts sparse. Semantic models that compress meaning. Decision records that encode authority. Retrieval systems that scope rather than sweep. The Manus team’s framing is apt: treat the file system as infinite external memory and the context window as a surgical instrument, pulling precisely what a specific inference step requires rather than pre-loading everything that might come up.
The arms race toward million-token context windows is a distraction. The real competitive advantage in agentic data systems will belong to the teams that figure out how to say no: what to keep out of the window, what to compress before inclusion, what to structure for the model’s architectural biases rather than a human reader’s preferences.
Context engineering isn’t about filling the window. It’s about earning every token you put in it.
Eric Simon is a data practitioner at Finch. He writes about data infrastructure, decision context, and the gaps between what our tools capture and what our organizations need to know at Beyond the Traverse.